
Basics : Decison Trees and Random Forest
Objective: Given the publicly available data from LendingClub.com, we will use lending data from 2007-2010 and try to classify and predict whether or not the borrower paid back their loan in full.
Source: Udemy | Python for Data Science and Machine Learning Bootcamp
Data used in the below analysis: link
#Import all the libraries for data analysis
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
#used to view plots within jupyter notebook
%matplotlib inline
sns.set_style("whitegrid") #setting view for plots, optional
loans = pd.read_csv('loan_data.csv') #import dataset
#view the data
loans.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 9578 entries, 0 to 9577
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 credit.policy 9578 non-null int64
1 purpose 9578 non-null object
2 int.rate 9578 non-null float64
3 installment 9578 non-null float64
4 log.annual.inc 9578 non-null float64
5 dti 9578 non-null float64
6 fico 9578 non-null int64
7 days.with.cr.line 9578 non-null float64
8 revol.bal 9578 non-null int64
9 revol.util 9578 non-null float64
10 inq.last.6mths 9578 non-null int64
11 delinq.2yrs 9578 non-null int64
12 pub.rec 9578 non-null int64
13 not.fully.paid 9578 non-null int64
dtypes: float64(6), int64(7), object(1)
memory usage: 1.0+ MB
loans.describe()
| credit.policy | int.rate | installment | log.annual.inc | dti | fico | days.with.cr.line | revol.bal | revol.util | inq.last.6mths | delinq.2yrs | pub.rec | not.fully.paid | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 9578.000000 | 9578.000000 | 9578.000000 | 9578.000000 | 9578.000000 | 9578.000000 | 9578.000000 | 9.578000e+03 | 9578.000000 | 9578.000000 | 9578.000000 | 9578.000000 | 9578.000000 |
| mean | 0.804970 | 0.122640 | 319.089413 | 10.932117 | 12.606679 | 710.846314 | 4560.767197 | 1.691396e+04 | 46.799236 | 1.577469 | 0.163708 | 0.062122 | 0.160054 |
| std | 0.396245 | 0.026847 | 207.071301 | 0.614813 | 6.883970 | 37.970537 | 2496.930377 | 3.375619e+04 | 29.014417 | 2.200245 | 0.546215 | 0.262126 | 0.366676 |
| min | 0.000000 | 0.060000 | 15.670000 | 7.547502 | 0.000000 | 612.000000 | 178.958333 | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 1.000000 | 0.103900 | 163.770000 | 10.558414 | 7.212500 | 682.000000 | 2820.000000 | 3.187000e+03 | 22.600000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 50% | 1.000000 | 0.122100 | 268.950000 | 10.928884 | 12.665000 | 707.000000 | 4139.958333 | 8.596000e+03 | 46.300000 | 1.000000 | 0.000000 | 0.000000 | 0.000000 |
| 75% | 1.000000 | 0.140700 | 432.762500 | 11.291293 | 17.950000 | 737.000000 | 5730.000000 | 1.824950e+04 | 70.900000 | 2.000000 | 0.000000 | 0.000000 | 0.000000 |
| max | 1.000000 | 0.216400 | 940.140000 | 14.528354 | 29.960000 | 827.000000 | 17639.958330 | 1.207359e+06 | 119.000000 | 33.000000 | 13.000000 | 5.000000 | 1.000000 |
loans.head(4)
| credit.policy | purpose | int.rate | installment | log.annual.inc | dti | fico | days.with.cr.line | revol.bal | revol.util | inq.last.6mths | delinq.2yrs | pub.rec | not.fully.paid | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | debt_consolidation | 0.1189 | 829.10 | 11.350407 | 19.48 | 737 | 5639.958333 | 28854 | 52.1 | 0 | 0 | 0 | 0 |
| 1 | 1 | credit_card | 0.1071 | 228.22 | 11.082143 | 14.29 | 707 | 2760.000000 | 33623 | 76.7 | 0 | 0 | 0 | 0 |
| 2 | 1 | debt_consolidation | 0.1357 | 366.86 | 10.373491 | 11.63 | 682 | 4710.000000 | 3511 | 25.6 | 1 | 0 | 0 | 0 |
| 3 | 1 | debt_consolidation | 0.1008 | 162.34 | 11.350407 | 8.10 | 712 | 2699.958333 | 33667 | 73.2 | 1 | 0 | 0 | 0 |
#visualize and explore data a little
plt.figure(figsize=(10,6))
loans[loans['credit.policy']==1]['fico'].hist(bins=30,color='red',alpha=.5,label='Credit Policy = 1')
loans[loans['credit.policy']==0]['fico'].hist(bins=30,alpha=.5,label='Credit Policy = 0')
plt.legend()
plt.xlabel('FICO')
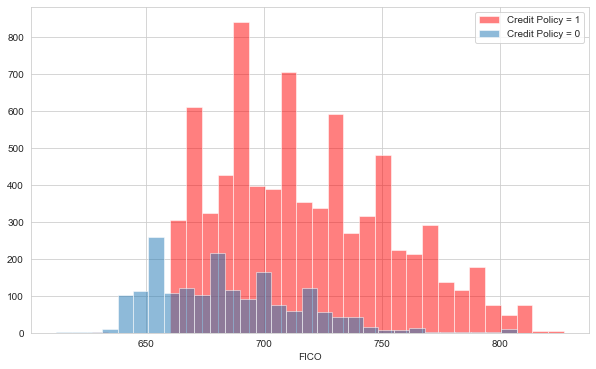
We can see that anyone with FICO score below 660 is not eligible for credit from LendingClub
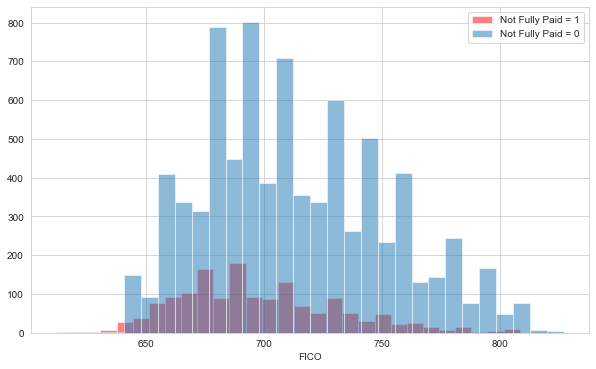
plt.figure(figsize=(10,6))
loans[loans['not.fully.paid']==1]['fico'].hist(bins=30,color='red',alpha=.5,label='Not Fully Paid = 1')
loans[loans['not.fully.paid']==0]['fico'].hist(bins=30,alpha=.5,label='Not Fully Paid = 0')
plt.legend()
plt.xlabel('FICO')
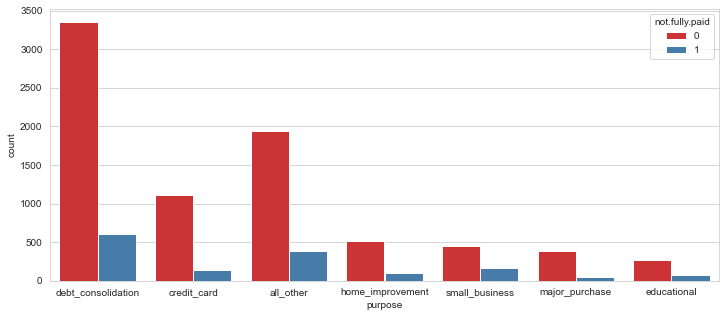
plt.figure(figsize=(12,5))
sns.countplot(x='purpose',data=loans,hue='not.fully.paid',palette='Set1')
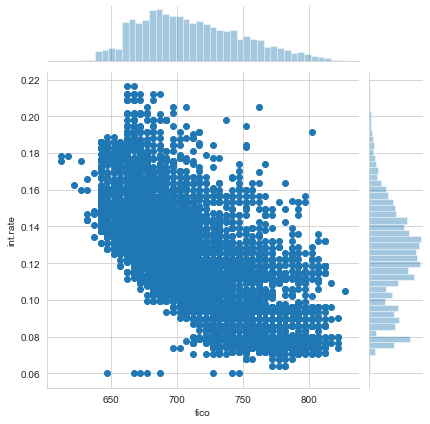
sns.jointplot(x='fico',y='int.rate',data=loans)
plt.figure(figsize=(10,6))
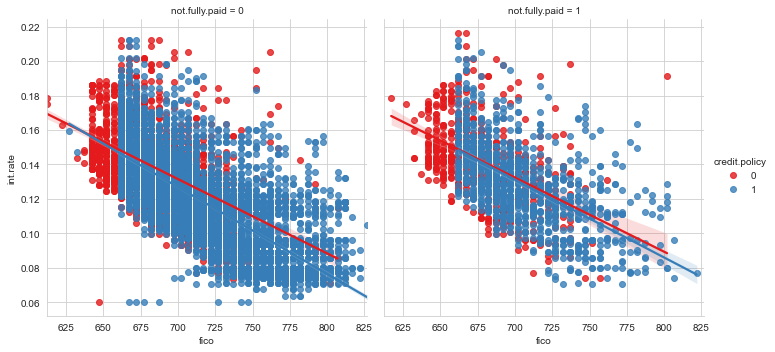
sns.lmplot(x='fico',y='int.rate',data=loans,col='not.fully.paid',hue='credit.policy',palette='Set1')
Clean and convert data in order to make it usable by ML algorithms
Purpose is a categorical column and thus needs to be converted to numerical one, using pd.get_dummies.
cat_feats = ['purpose']
final_data = pd.get_dummies(loans,columns=cat_feats,drop_first=True)
final_data
| credit.policy | int.rate | installment | log.annual.inc | dti | fico | days.with.cr.line | revol.bal | revol.util | inq.last.6mths | delinq.2yrs | pub.rec | not.fully.paid | purpose_credit_card | purpose_debt_consolidation | purpose_educational | purpose_home_improvement | purpose_major_purchase | purpose_small_business | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0.1189 | 829.10 | 11.350407 | 19.48 | 737 | 5639.958333 | 28854 | 52.1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 1 | 1 | 0.1071 | 228.22 | 11.082143 | 14.29 | 707 | 2760.000000 | 33623 | 76.7 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 2 | 1 | 0.1357 | 366.86 | 10.373491 | 11.63 | 682 | 4710.000000 | 3511 | 25.6 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 3 | 1 | 0.1008 | 162.34 | 11.350407 | 8.10 | 712 | 2699.958333 | 33667 | 73.2 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 4 | 1 | 0.1426 | 102.92 | 11.299732 | 14.97 | 667 | 4066.000000 | 4740 | 39.5 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 9573 | 0 | 0.1461 | 344.76 | 12.180755 | 10.39 | 672 | 10474.000000 | 215372 | 82.1 | 2 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 9574 | 0 | 0.1253 | 257.70 | 11.141862 | 0.21 | 722 | 4380.000000 | 184 | 1.1 | 5 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 9575 | 0 | 0.1071 | 97.81 | 10.596635 | 13.09 | 687 | 3450.041667 | 10036 | 82.9 | 8 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
| 9576 | 0 | 0.1600 | 351.58 | 10.819778 | 19.18 | 692 | 1800.000000 | 0 | 3.2 | 5 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
| 9577 | 0 | 0.1392 | 853.43 | 11.264464 | 16.28 | 732 | 4740.000000 | 37879 | 57.0 | 6 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
9578 rows × 19 columns
We can see all the reasons under purpose are now added in the columns with values as 0 or 1
Split data into Train and Test
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(final_data.drop('not.fully.paid',axis=1), final_data['not.fully.paid'],
test_size=0.3, random_state=101)
Train using Decison Tree and evaluate it
from sklearn.tree import DecisionTreeClassifier
dtree = DecisionTreeClassifier()
dtree.fit(X_train,y_train)
DecisionTreeClassifier()
predictions = dtree.predict(X_test)
from sklearn.metrics import classification_report,confusion_matrix
print(confusion_matrix(y_test,predictions))
[[1995 436]
[ 344 99]]
print(classification_report(y_test,predictions))
precision recall f1-score support
0 0.85 0.82 0.84 2431
1 0.19 0.22 0.20 443
accuracy 0.73 2874
macro avg 0.52 0.52 0.52 2874
weighted avg 0.75 0.73 0.74 2874
Train using Random Forest and evaluate it
from sklearn.ensemble import RandomForestClassifier
rdf = RandomForestClassifier(n_estimators=400)
rdf.fit(X_train,y_train)
RandomForestClassifier(n_estimators=400)
rdf_predictions = rdf.predict(X_test)
print(confusion_matrix(y_test,rdf_predictions))
[[2422 9]
[ 431 12]]
print(classification_report(y_test,rdf_predictions))
precision recall f1-score support
0 0.85 1.00 0.92 2431
1 0.57 0.03 0.05 443
accuracy 0.85 2874
macro avg 0.71 0.51 0.48 2874
weighted avg 0.81 0.85 0.78 2874