
Basics : K-Nearest Neighbors
Objective: Given some “Classified Data”, train the model to categorize data points.
Source: Udemy | Python for Data Science and Machine Learning Bootcamp
Data used in the below analysis: link
#import necessary libraries for analysis
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
#set this to view plots in jupyter notebook
%matplotlib inline
sns.set_style('whitegrid')
knn_data = pd.read_csv('KNN_Project_Data') #read data into dataframe
knn_data.head(3) #view some data entries
| XVPM | GWYH | TRAT | TLLZ | IGGA | HYKR | EDFS | GUUB | MGJM | JHZC | TARGET CLASS | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1636.670614 | 817.988525 | 2565.995189 | 358.347163 | 550.417491 | 1618.870897 | 2147.641254 | 330.727893 | 1494.878631 | 845.136088 | 0 |
| 1 | 1013.402760 | 577.587332 | 2644.141273 | 280.428203 | 1161.873391 | 2084.107872 | 853.404981 | 447.157619 | 1193.032521 | 861.081809 | 1 |
| 2 | 1300.035501 | 820.518697 | 2025.854469 | 525.562292 | 922.206261 | 2552.355407 | 818.676686 | 845.491492 | 1968.367513 | 1647.186291 | 1 |
Since this data is artificial, we would view all the features for better understanding
#pair plot of the entire data
sns.pairplot(data=knn_data,hue='TARGET CLASS')

Standardize the variables
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(knn_data.drop('TARGET CLASS',axis=1))
StandardScaler()
scaled_version = scaler.transform(knn_data.drop('TARGET CLASS',axis=1)) #scaled the features
#convert the scaled array into a DataFrame
knn_data_scaled = pd.DataFrame(scaled_version,columns=knn_data.columns[:-1])
knn_data_scaled.head() #check the head to see if scaling worked
| XVPM | GWYH | TRAT | TLLZ | IGGA | HYKR | EDFS | GUUB | MGJM | JHZC | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.568522 | -0.443435 | 1.619808 | -0.958255 | -1.128481 | 0.138336 | 0.980493 | -0.932794 | 1.008313 | -1.069627 |
| 1 | -0.112376 | -1.056574 | 1.741918 | -1.504220 | 0.640009 | 1.081552 | -1.182663 | -0.461864 | 0.258321 | -1.041546 |
| 2 | 0.660647 | -0.436981 | 0.775793 | 0.213394 | -0.053171 | 2.030872 | -1.240707 | 1.149298 | 2.184784 | 0.342811 |
| 3 | 0.011533 | 0.191324 | -1.433473 | -0.100053 | -1.507223 | -1.753632 | -1.183561 | -0.888557 | 0.162310 | -0.002793 |
| 4 | -0.099059 | 0.820815 | -0.904346 | 1.609015 | -0.282065 | -0.365099 | -1.095644 | 0.391419 | -1.365603 | 0.787762 |
We can see that the data is now in a standard scale and has closer values as compared to huge values in the initial dataset
Split the data into train and test
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(knn_data_scaled,knn_data['TARGET CLASS'],test_size=0.3,random_state=101)
Apply KNN on the data
from sklearn.neighbors import KNeighborsClassifier
KNN = KNeighborsClassifier(n_neighbors=1)
KNN.fit(X_train,y_train)
KNeighborsClassifier(n_neighbors=1)
Predictions and Evaluations
predictions = KNN.predict(X_test)
from sklearn.metrics import classification_report, confusion_matrix
print(confusion_matrix(y_test,predictions))
[[109 43]
[ 41 107]]
print(classification_report(y_test,predictions))
precision recall f1-score support
0 0.73 0.72 0.72 152
1 0.71 0.72 0.72 148
accuracy 0.72 300
macro avg 0.72 0.72 0.72 300
weighted avg 0.72 0.72 0.72 300
Choosing a K value for better accuracy
We will use the elbow method to pick a better K value
error = []
for i in range (1,40):
KNN = KNeighborsClassifier(n_neighbors=i)
KNN.fit(X_train,y_train)
pred_i = KNN.predict(X_test)
error.append(np.mean(y_test != pred_i))
#view the error list
print(error)
[0.28, 0.29, 0.21666666666666667, 0.22, 0.20666666666666667, 0.21, 0.18333333333333332, 0.19, 0.19, 0.17666666666666667, 0.18333333333333332, 0.18333333333333332, 0.18333333333333332, 0.18, 0.18, 0.18, 0.17, 0.17333333333333334, 0.17666666666666667, 0.18333333333333332, 0.17666666666666667, 0.18333333333333332, 0.16666666666666666, 0.18, 0.16666666666666666, 0.17, 0.16666666666666666, 0.17333333333333334, 0.16666666666666666, 0.17333333333333334, 0.16, 0.16666666666666666, 0.17333333333333334, 0.17333333333333334, 0.17, 0.16666666666666666, 0.16, 0.16333333333333333, 0.16]
#plot the error vs K values to better view the result
plt.figure(figsize=(16,7))
plt.plot(range(1,40),error,linestyle='--',color='blue',marker='o',markerfacecolor='red',markersize=10)
plt.xlabel('Values of K')
plt.ylabel('Mean Error')
plt.title('Error rate vs K Value')
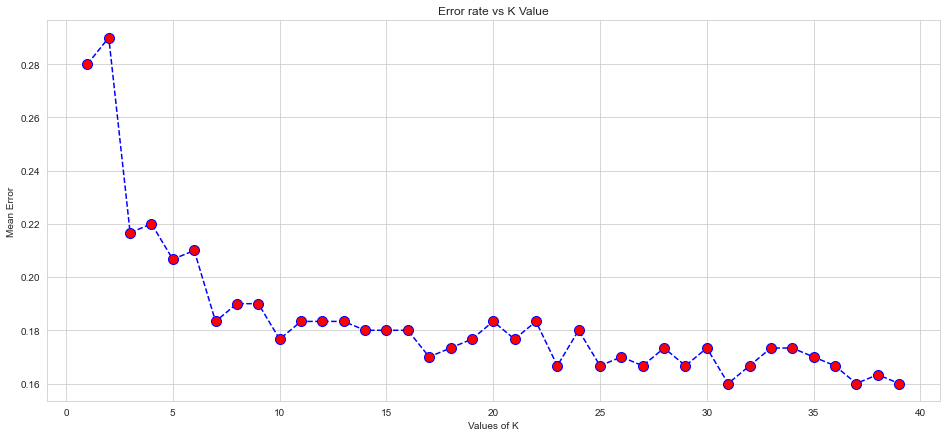
Retraining the data with the better K Value as per the plot above
Choosing K value as 31
KNN = KNeighborsClassifier(n_neighbors=31)
KNN.fit(X_train,y_train)
predictions = KNN.predict(X_test)
print(confusion_matrix(y_test,predictions))
[[123 29]
[ 19 129]]
print(classification_report(y_test,predictions))
precision recall f1-score support
0 0.87 0.81 0.84 152
1 0.82 0.87 0.84 148
accuracy 0.84 300
macro avg 0.84 0.84 0.84 300
weighted avg 0.84 0.84 0.84 300