
Basics : Logistic Regression
Objective: To figure out if a user clicked on an advertisement and predict whether or not they will click on an ad based off the features of that user.
Source: Udemy | Python for Data Science and Machine Learning Bootcamp
Data used in the below analysis: link
#importing libraries we'll need
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
#used to view plots within jupyter notebook
%matplotlib inline
sns.set_style('whitegrid')
#read data from csv file
ad_data = pd.read_csv('advertising.csv')
ad_data.head(2)#view data
| Daily Time Spent on Site | Age | Area Income | Daily Internet Usage | Ad Topic Line | City | Male | Country | Timestamp | Clicked on Ad | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 68.95 | 35 | 61833.90 | 256.09 | Cloned 5thgeneration orchestration | Wrightburgh | 0 | Tunisia | 2016-03-27 00:53:11 | 0 |
| 1 | 80.23 | 31 | 68441.85 | 193.77 | Monitored national standardization | West Jodi | 1 | Nauru | 2016-04-04 01:39:02 | 0 |
#view some info on the dataset
ad_data.describe()
| Daily Time Spent on Site | Age | Area Income | Daily Internet Usage | Male | Clicked on Ad | |
|---|---|---|---|---|---|---|
| count | 1000.000000 | 1000.000000 | 1000.000000 | 1000.000000 | 1000.000000 | 1000.00000 |
| mean | 65.000200 | 36.009000 | 55000.000080 | 180.000100 | 0.481000 | 0.50000 |
| std | 15.853615 | 8.785562 | 13414.634022 | 43.902339 | 0.499889 | 0.50025 |
| min | 32.600000 | 19.000000 | 13996.500000 | 104.780000 | 0.000000 | 0.00000 |
| 25% | 51.360000 | 29.000000 | 47031.802500 | 138.830000 | 0.000000 | 0.00000 |
| 50% | 68.215000 | 35.000000 | 57012.300000 | 183.130000 | 0.000000 | 0.50000 |
| 75% | 78.547500 | 42.000000 | 65470.635000 | 218.792500 | 1.000000 | 1.00000 |
| max | 91.430000 | 61.000000 | 79484.800000 | 269.960000 | 1.000000 | 1.00000 |
ad_data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000 entries, 0 to 999
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Daily Time Spent on Site 1000 non-null float64
1 Age 1000 non-null int64
2 Area Income 1000 non-null float64
3 Daily Internet Usage 1000 non-null float64
4 Ad Topic Line 1000 non-null object
5 City 1000 non-null object
6 Male 1000 non-null int64
7 Country 1000 non-null object
8 Timestamp 1000 non-null object
9 Clicked on Ad 1000 non-null int64
dtypes: float64(3), int64(3), object(4)
memory usage: 78.2+ KB
#Plots to explore the dataset
sns.distplot(ad_data['Age'],bins=30,kde=False)
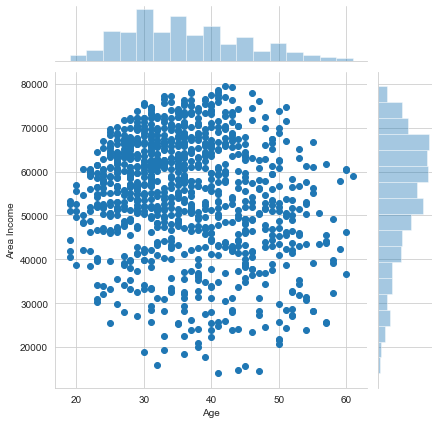
sns.jointplot(x='Age',y='Area Income',data=ad_data)
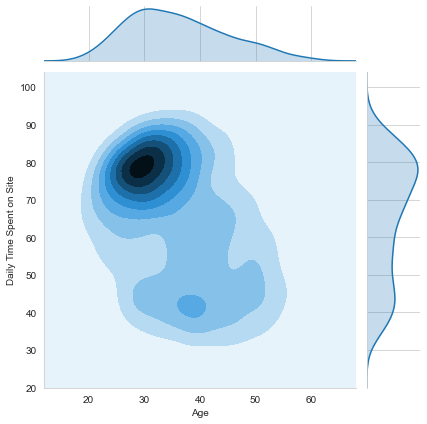
sns.jointplot(x='Age',y='Daily Time Spent on Site',data=ad_data,kind='kde')
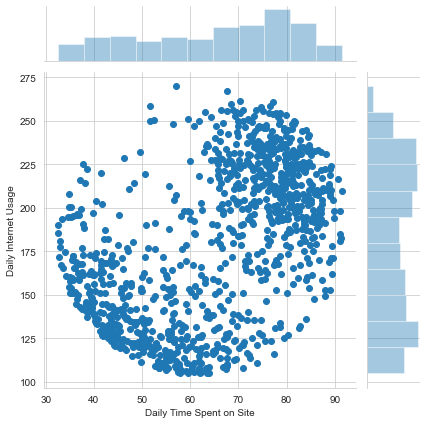
sns.jointplot(x='Daily Time Spent on Site',y='Daily Internet Usage',data=ad_data)
sns.pairplot(data=ad_data,hue='Clicked on Ad',palette='bwr')
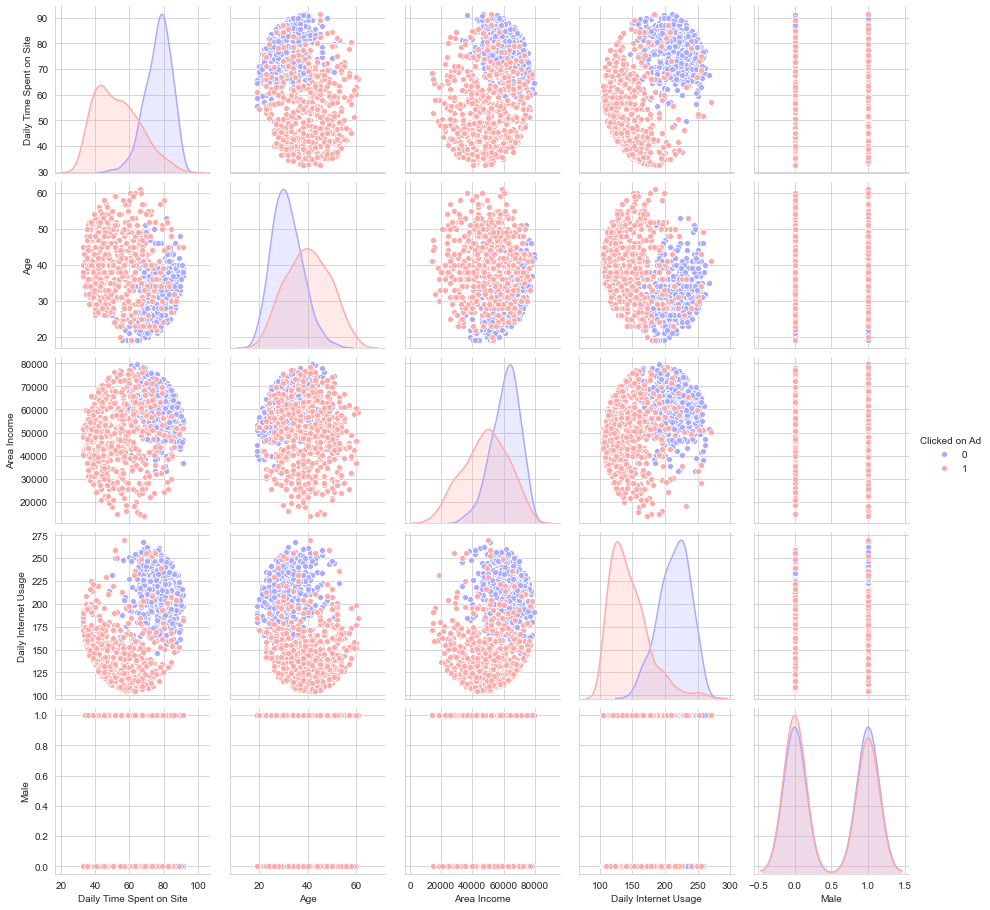
Now we start training the model to predict whether the user clicked on Ad
#import required libraries and split the data into train and test
from sklearn.model_selection import train_test_split
ad_data.columns
Index(['Daily Time Spent on Site', 'Age', 'Area Income',
'Daily Internet Usage', 'Ad Topic Line', 'City', 'Male', 'Country',
'Timestamp', 'Clicked on Ad'],
dtype='object')
We can get rid of ‘Ad Topic Line’, ‘City’,’Country’,’Timestamp’ as these are not numeric column and we are not dealing with non-numeric data to train models yet
X = ad_data[['Daily Time Spent on Site', 'Age', 'Area Income',
'Daily Internet Usage','Male',]]
y = ad_data['Clicked on Ad']
from sklearn.model_selection import train_test_split
X_train,X_test, y_train,y_test =train_test_split(X, y, test_size=0.3, random_state=101)
#import Logistic Regression model and fit data
from sklearn.linear_model import LogisticRegression
logmodel = LogisticRegression()
logmodel.fit(X_train,y_train)
LogisticRegression()
predictions = logmodel.predict(X_test)
#Get important metrics to evaluate model
from sklearn.metrics import classification_report
print(classification_report(y_test,predictions))
precision recall f1-score support
0 0.91 0.95 0.93 157
1 0.94 0.90 0.92 143
accuracy 0.93 300
macro avg 0.93 0.93 0.93 300
weighted avg 0.93 0.93 0.93 300